改訂版 ピボットテーブルを使用しないクロス集計
August 18, 2023
はじめに
最近、立て続けに記事をアップしております。。。
2017年8月に本ブログにアップした次の記事、
ピボットテーブルを使用しないクロス集計 – tamo’s blog
ですが、これまでで1.3万ビューということで、割と多くの方にご覧になられているようです。
ただあれからもう6年、少々内容が古くなってしまいました。
2017年に記載した記事では、配列数式を使用していましたが、今やスピル機能が使用できます。
今回は、ピボットテーブルでのクロス集計についておさらいしながら、ピボットテーブルも良いけど、条件統計関数とスピル機能を使用することでクロス集計できますよー、というお話です。
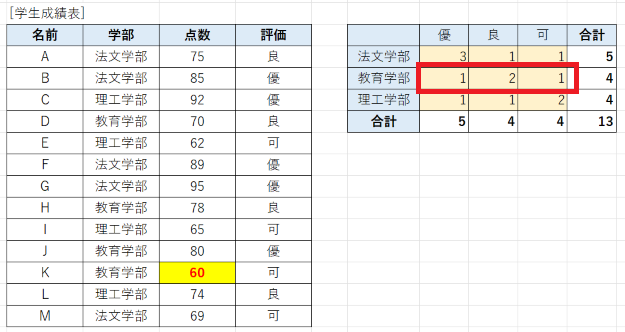
まずは、今回サンプルで使用するワークシートです。簡単なリストとして学生成績表をサンプルで使用します。学生の所属学部と点数と評価が記載された簡単な表です。
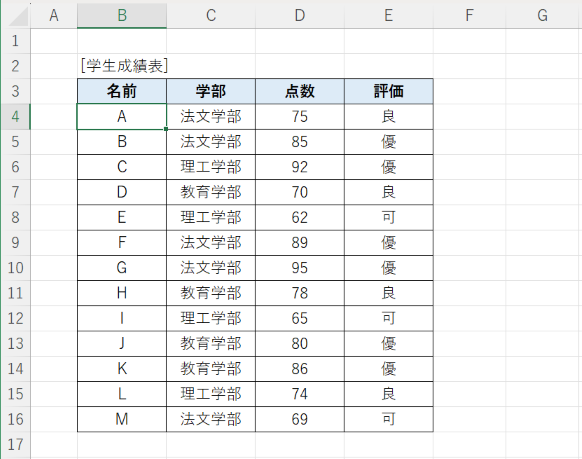
これを、学部ごと評価ごとに、学生数をカウントするクロス集計、
| 優 | 良 | 可 | 合計 | |
|---|---|---|---|---|
| 法文学部 | 3 | 1 | 1 | 5 |
| 教育学部 | 2 | 2 | 0 | 4 |
| 理工学部 | 1 | 1 | 2 | 4 |
| 合計 | 6 | 4 | 3 | 13 |
を作成してみようと思います。
ピボットテーブルを使用したクロス集計
使用方法
では、よくExcelの入門で良く紹介されている、ピボットテーブル機能を使用したクロス集計のやり方をおさらいしてみます。
まず、リストのセル範囲 B3:E16 を選択します。
もし、セルB2に何も入力されていなければ、リスト内の任意のセル(例えば B3)を選択するだけでOKですが、そうでなければ、きちんと範囲選択してやる必要があります。なぜなら、リストは空白行と空白列に囲まれていなければ、Excelがリストを正しく自動認識してくれないからです。
次に、「挿入」タブの「テーブル」グループにある「ピボットテーブル」を選択し、「テーブルまたは範囲から」をクリックします。
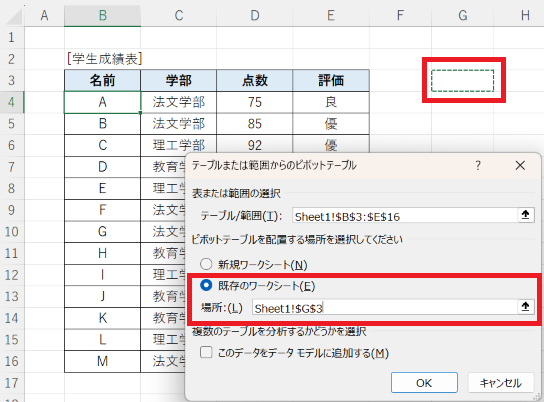
ウィンドウ「テーブルまたは範囲からのピボットテーブル」が表示されるので、そこで「既存のワークシート」を選択した後、その「場所」として、ピボットテーブルを挿入するセル(例えば、セル G3)を選択します。その後、「OK」ボタンをクリックします。
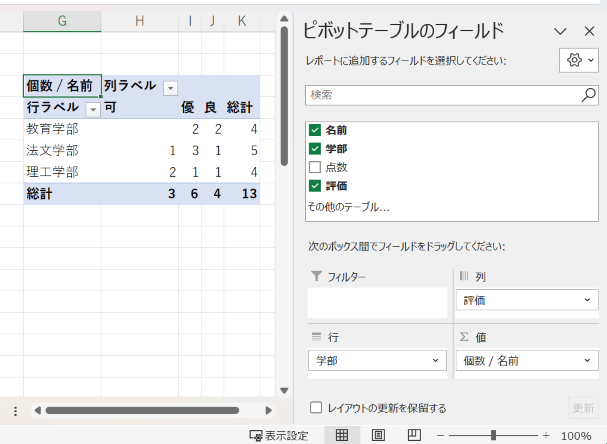
ピボットテーブルのフィールドとして、
-
名前
-
学部
-
評価
の3つのフィールドにチェックを入れます。すると、「行」ボックスに全てのフィールドが入ってしまいますが、「列」ボックスに「評価」、「値」ボックスに「名前」、それぞれドラッグして移動させます。
ピボットテーブルの各フィールドが
-
「列」: 「評価」
-
「行」: 「学部」
-
「値」: 「個数/名前」
になっていればOKです。これでピボットテーブルは完成となります。
ピボットテーブルの問題点
ピボットテーブルの大きな問題点は、リストのデータを変更しても、クロス集計の結果が自動で更新されないことです。
例えば、教育学部のKさんの点数を 86 → 60 に変えて、評価を「優」から「可」変えてみます。
変更前は、教育学部の学生は4人いて、「優」が2人、「良」が2人です。
これが、変更後は、「優」が1人、「良」が2人、「可」が1人とならなければならないはずです。
ですが、、、
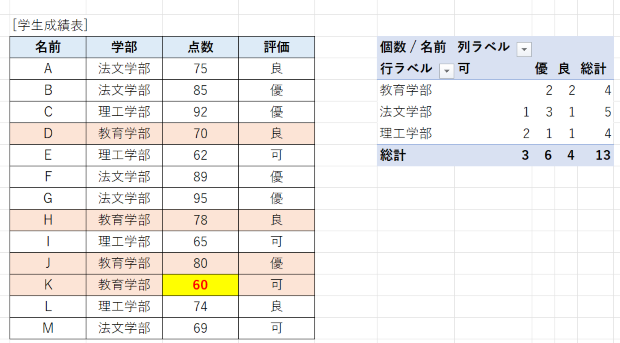
このとおり、セルの値を変えても集計結果は更新されません。
集計結果を更新させるためには、ピボットテーブルの結果(クロス集計表)内の任意のセル選択し、メニュー「ピボットテーブル分析」を選択、「更新」のさらに「更新」をクリックする必要があります。
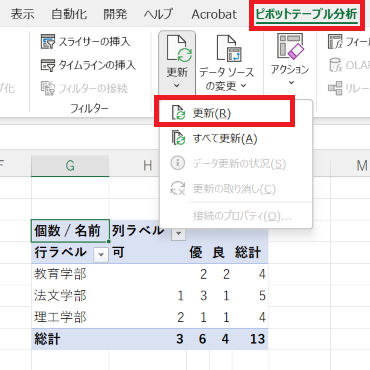
「更新」ボタンをクリックするだけやん、と思われがちですが、結構その「更新」をし忘れることがあるのです。クリティカルな集計結果を提示や報告しなければならない場面では、結構な問題です。
条件統計関数とスピル機能を使ったクロス集計
ピボットテーブルを使用しないクロス集計
前回のブログ記事では、ピボットテーブルを使わないクロス集計として、
-
データベース関数とデータテーブル機能を使ったクロス集計
-
条件統計関数と配列数式を使ったクロス集計
を紹介していました。
これらは、特にデータテーブル機能を使った例は、Lotus 1-2-3 にも同等の機能があって、30年近く前から講習会とかで紹介していますので、昔からある機能です。
配列数式は、対象となるセル範囲を選択した後、数式を入力する際に「Ctrl」+「Shift」+「Enter」キーを(同時に)押して入力する数式のことです。入力するキーの頭文字をとって「CSE数式」とも呼ばれます。数式は統計関数などが配列数式に対応しています。
Excelも、Microsoft 365 のサブスクのバージョンになって初めて「スピル機能」というものが利用できるようになりました。
スピルは、配列数式と違って、あらかじめセル範囲を選択するのではなく、ある1つのセルに、数式の中に、特に関数の引数として、セル範囲を指定した数式を入力すると、その数式を入力した1つのセルから、その下あるいは右のセル範囲に、数式があふれ出していく(spill)というイメージです。
実際の使用例
まずは、あらかじめ、次の図のように、セル範囲 G3:K7 に、学部名や評価の項目を入力して、クロス集計用の表を準備しておきます。
合計欄は、それぞれ行ごとの合計、列ごとの合計が計算されるよう、SUM関数をそれぞれ入力しておきます。
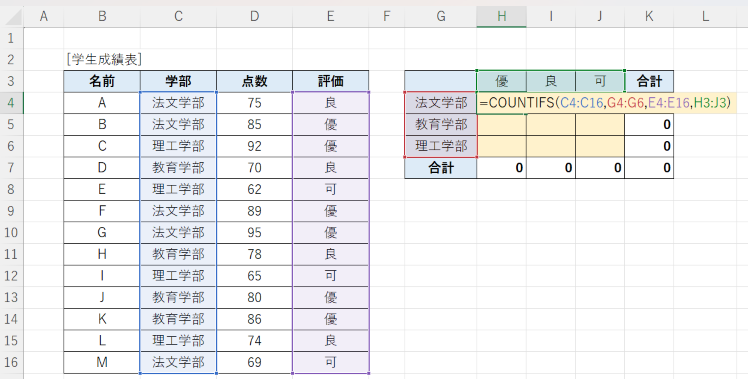
後は、図のように、セル H4 に、
=COUNTIFS(C4:C16,G4:G6,E4:E16,H3:J3)
と入力するだけです。
COUNTIFS関数は、あるセル範囲において、ある複数の条件に合致したものだけ(個数)をカウントする関数です。
-
第1引数は、「条件範囲1」で、学生成績表の「学部」の列、
C4:C16 -
第2引数は、「検索条件1」で、クロス集計表の左の列(各学部名が入力されている)列、
G4:G6 -
第3引数は、「条件範囲2」で、学生成績表の「評価」の列、
E4:E16 -
第4引数は、「検索条件2」で、クロス集計表の右の行(各評価が入力されている)列、
H3:J3
数式を入力したら、普通に「Enter」キーを押すだけです。
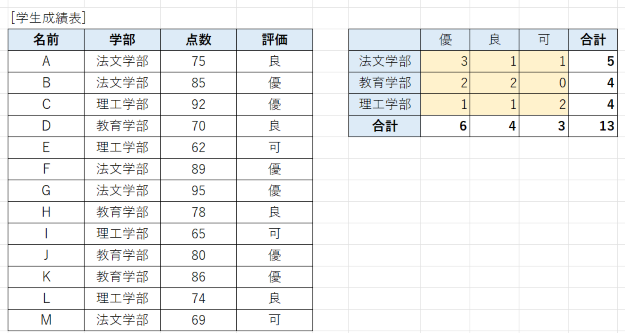
数式をセル H4 に入力しただけで、セル H4:J6 にあふれるように数式が適用されています。結果、ピボットテーブルで作成したクロス集計と同等の結果になっています。
ただ、ピボットテーブルと違って、リスト内のデータ(ある学生の評価)を変更すると、Excelの再計算機能により、自動的にクロス集計結果がきちんと更新されます。
また、クロス集計の表については、書式や構成は任意で自由に設定できるので、ピボットテーブルと違って汎用性があります。
リストをテーブル化
リスト(ここでは学生成績表)をテーブル化すると、列(フィールド)の指定等が項目名(フィールド名)で設定できるようになり、更に、行(レコード)が増えても対応してくれるようになります。
リスト(セル範囲 B3:E16)を選択した後、「ホーム」タブの「テーブルとして書式設定」を選択、適当なデザインをクリックします。
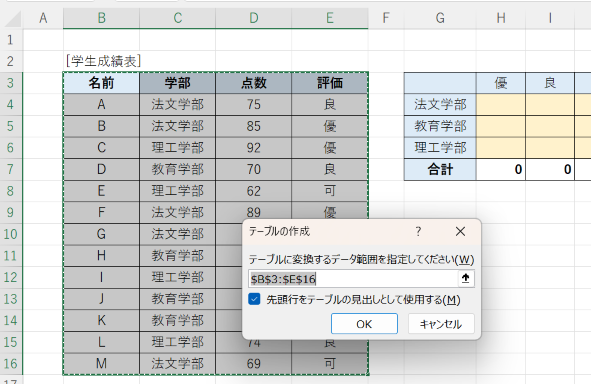
すると、次図のようなウィンドウが出るので、指定セル範囲に間違いがないことを確認したら「OK」ボタンをクリックします。
セル H4 に入力する数式は、次のように設定できます。
=COUNTIFS(テーブル1[学部],G4:G6,テーブル1[評価],H3:J3)

UNIQUE関数を使用して汎用化
テーブル化したところで、セル範囲 C4:C16 が「テーブル1[学部]」に変わっただけやん、って言われそうですが、これから説明することで、おおっ、便利かも~、って思ってくれることを期待します。
次のように、罫線を引いただけのクロス集計表エリアに、次のようにセル G4 に、UNIQUE関数を入力することで、クロス集計に設定すべき項目を自動入力させることができます。
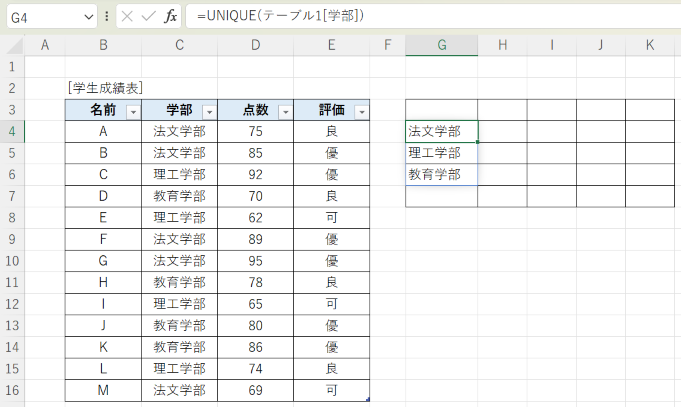
=UNIQUE(テーブル1[学部])
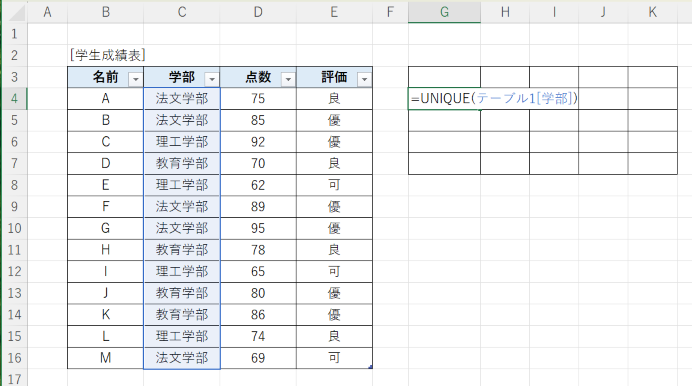
UNIQUE関数は、引数に指定したセル範囲のデータの内、重複を排除したものを、数式を入力した直下の行に出力する関数で、スピル用関数として使用します。結果、次のとおり、G列にぞろっと出てきます。
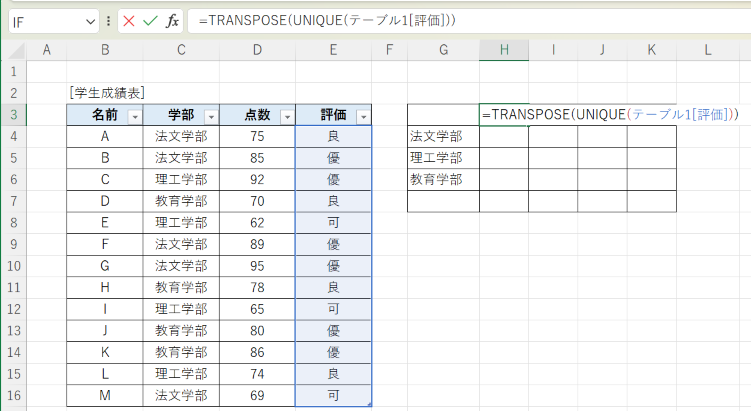
同様に、今度はクロス集計表の列側、つまり評価の項目も、テーブル「学生成績表」からUNIQUE関数で取得したいところですが、UNIQUE関数はその入力した配下行に出力されてしまうので、それを列方向への出力に変換するTRANSPOSE関数でネストします。セル H3 に次のように入力します。
=TRANSPOSE(UNIQUE(テーブル1[評価]))
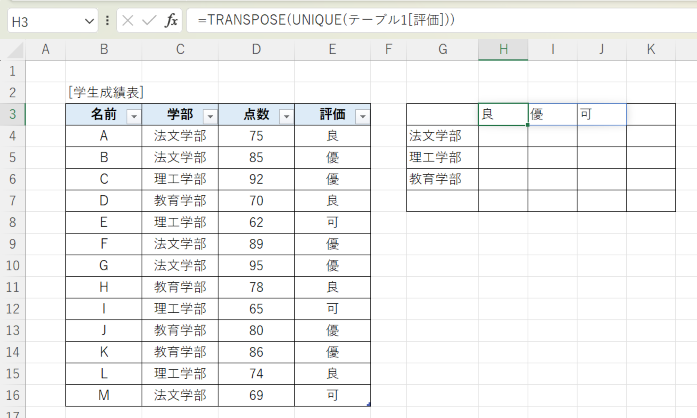
結果は、こうなります。これでクロス集計の項目は自動的に設定することが可能ということがお分かりなられたかと思います。
再度、これまでと同様にセル H4 に、次のように入力しようとすると、
=COUNTIFS(C4:C16,G4:G6,E4:E16,H3:J3)
実際の数式は、このように入力されます。
=COUNTIFS(テーブル1[学部],G4#,テーブル1[評価],H3#)
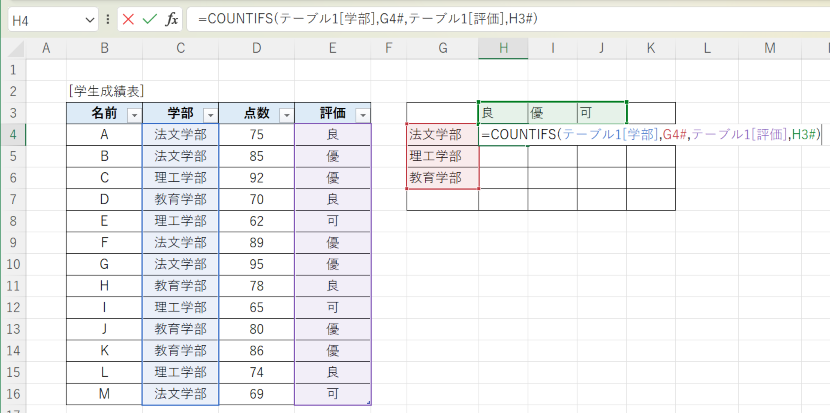
結果は、これまでと同等です。
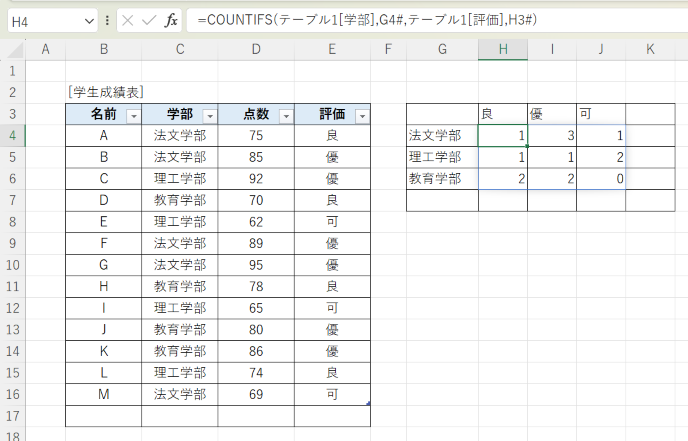
数式内の「G4#」や「H3#」の「#」が付いているのは、それがスピルで数式が入力されているセル範囲を示します。すなわち、「G4#」はセル G4 に入力された数式によってスピル出力された範囲、「H3#」はセル H3 に入力された数式によってスピル出力された範囲を意味します。
ここからが本領発揮です。
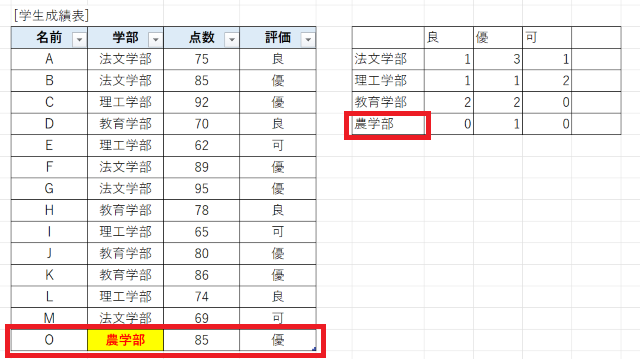
例えば、クロス集計表に存在しない学部(例えば「農学部」)の学生のデータを追加したとします。すると次図のようにクロス集計表にもその学部名が入り、集計の対象となります。
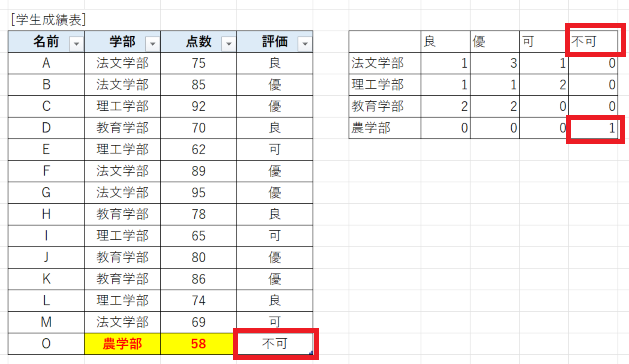
そして、その評価も「不可」という新たな評価盲目が増えてしまった場合でも、次のようにきちんと対応してくれます。
UNIQUE関数は、その項目が出現した順に重複排除した結果が出力されるため、「良」→「優」→「可」の順番になってしまっています。SORT関数でネストすることによって、一応ソートしてくれます。でもその場合でも、「可」→「優」→「良」の文字コード順?(読み順?)になってしまいます。「A優」、「B良」、「C可」のように、あらかじめソートを考慮した形でデータを入れておけば良いですね。
ピボットテーブルにおいても、その対象のリストをテーブル化すれば、後から追加したデータや、集計対象にない項目名に対しても、きちんと対応してくれますが、いちいち「更新」を操作をしなければなりません。
とはいっても、大量のデータをクロス集計する場合など、ピボットテーブルの機能は捨てがたいので、今回の条件統計関数とスピルを使ったものについては、ちょっとしたデータリストがあって、このクロス集計結果表をちょっと横っちょに表示させておきたい、というような場面で多用されてはいかがでしょうか。